A machine that can categorise images and generate captions automatically is a potentially useful tool. There have been many attempts to use deep learning and neural networks for this purpose. But they are not efficient in connecting the background and foreground details of the images.
Himanshu Sharma and Swati Srivastava from the Institute of Engineering and Technology, GLA University, Mathura, recently tackled the problem. Most previous attempts, they realised, relied on object pattern recognition, with or without region attributes. So they first surveyed available methods to integrate the objects within a region and their semantic relationships with other objects and other regions.
For the experiments, the researchers accessed large data sets with captioned images: the Microsoft Common Objects in Context, the novel object captioning at scale benchmark and Flickr30k data sets.
They input images into a region proposal network. The network identifies object patterns and regional features. To integrate data from subspaces within each image, the researchers used a multihead transformer model. The model integrates data from both the objects as well as the regions.
The problem now was to relate the different parts or regions of the image. The scientists used the context-aware graph neural network to combine extracted objects and identified significant relations using interactive learning. Thus, a local relation network is formed among objects and among regions.
To capture the features of objects in relation to the environment, the team used a multi-level attention mechanism.
They routed the output from the multi-level attention mechanism as input to a transformer-based caption decoder, a language model which generates sentences that are up to 30 words long.
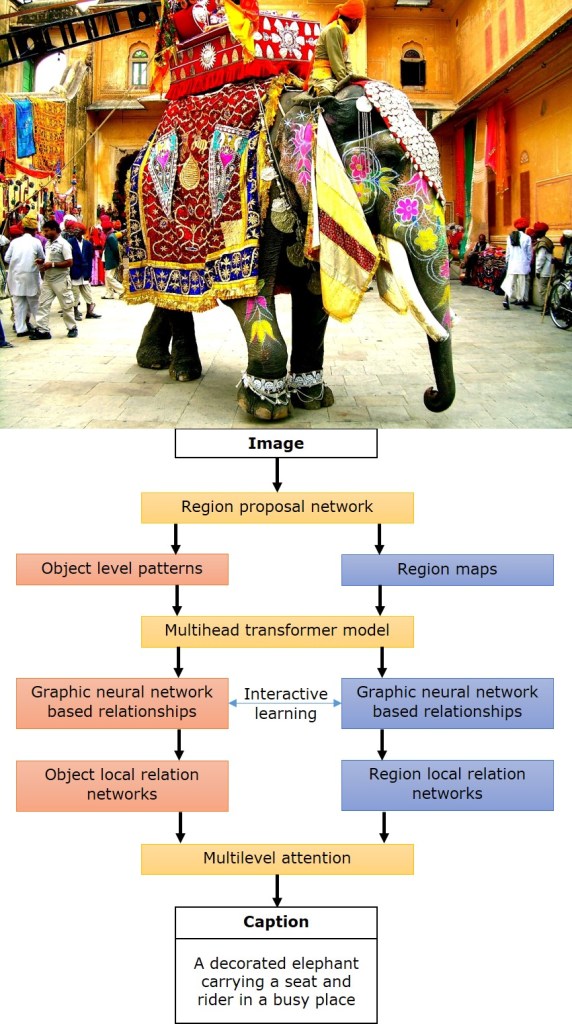
A graphical representation of the automatic caption generator framework by Karthic A
Out of the images from the MSCOCO, Nocaps and Flickr30k data sets, the researchers used more than 100 000 images for training, 46 000 for validating and 56 000 for testing the tool. The total training time was 41 hours.
The researchers then evaluated the captions generated using standard metrics.
“Our model generates better captions in most cases but sometimes faces problems with some out-of-domain images”, says, Swati Srivastava, GLA University, Mathura. “As more images are included in training set, this will reduce”
“An optical character recognition feature could also be incorporated to extract text in images and to improve the content of the captions,” adds Himanshu Sharma, her colleague.
Another possibility that they foresee is adding a text to speech engine into the system to help the visually challenged get a quick idea of images.
While the team continues tweaking their research, this tool can be immediately useful for searching and shortlisting relevant images in large datasets.
Neural Processing Letters, 1573-773X,(2022);
DOI: 10.1007/s11063-022-11106-y
Reported by Karthic A
SIIPL, Pune
*This report was written during the 3rd online workshop on science writing organised by Current Science.
STEAMindiaReports: free-to-use science news for Indian media outlets

Leave a comment